摘要
针对水文资料缺乏流域机器学习模型建模困难的问题,本文提出了基于长短期记忆神经网络(LSTM)的区域化洪水预报方法。对水文气候相似区内各流域的水文及地形地貌特征数据进行归一化处理,以消除局地因素的影响,从而构建相似区内建模统一数据集,扩大样本数量,为建立乏资料流域洪水预报模型提供了可能。本文选择胶东半岛作为研究区进行应用研究。为验证区域化模型在不同场景中的应用效果,设计了预报流域数据不参与建模,而仅根据区域内其他流域资料建模(区域化模型Ⅰ),以及预报流域的部分数据参与建模(区域化模型Ⅱ)两种情景;此外,选取仅根据预报流域数据训练的单流域模型作为基准模型进行对比分析。结果表明,对本次研究的水文资料短缺流域,两种区域化模型均取得了较好效果,且都优于单流域模型。相较而言,考虑了预报流域数据的区域化模型精度更高,说明在区域化LSTM构建中融入预报流域的数据,可进一步提升区域化模型的精度。研究成果可为乏资料地区的洪水预报提供参考。
Abstract
Aiming at the difficulty of hydrological modeling in hydrological data-scarce catchments, a regional flood forecasting method based on long-short term memory neural network (LSTM) was proposed in this paper. Through scalarizing the data of topographic and geomorphological factors of each catchment in the same hydroclimatic similarity zone, the influence of local factors could be eliminated. On this basis, a unified modeling dataset in a similarity zone was constructed and the sample size was effectively expanded, which provided a possibility for the establishment of flood forecasting models in the data-sparse catchments. The Jiaodong Peninsula was selected as the study area in this study. In order to verify the application effect of the regional model in different scenarios, two regional modeling schemes were designed in this paper. To be specific, the first scheme was to construct a regional model based on the data of other basins in the similarity zone, without the participation of the data of the forecast basin (regional model Ⅰ). The second scheme was to construct a regional model with the data both from the forecast basin and other basins in the same region (regional model Ⅱ). In addition, the “single-basin model”, which was trained only with forecast basin's data, was selected as a benchmark model. Results indicated that, for data-scarce basins in this study, both regional models exhibited high accuracy and were superior to single-basin model. Comparatively, the regional model that incorporated data from the forecast basin outperformed the other regional model, suggesting that the accuracy of the regional model could be further improved if the data of the forecast basin was incorporated into model construction. The study can provide a reference for flood forecasting in data-scarce catchments.
近年来,长短期记忆神经网络(long-short term memory neural network,LSTM)[1]机器学习模型在水文领域得到较广泛的关注和研究。该模型将记忆单元引入循环神经网络(recurrent neural network,RNN)[2]的隐藏层中,以门元件控制时间序列中的记忆信息,能够有效描述时序数据间信息的长时依赖特征;而且,其较强的自适应性、时间序列非线性拟合能力、并行计算能力,适合于描述流域降雨径流这类关系复杂且随时间变化的问题[3];因此,该模型在水文模拟预报中得到重视和应用[4-6]。刘扬等[7]、Hu等[8]以及陶思铭等[9]分别实现将LSTM模型应用于实时洪水预报、径流日尺度预报以及中长期预测中,表明LSTM模型能够模拟和预测时间序列的长短程变化,适用于多种时间尺度的水文模拟。此外,许多研究比较分析了LSTM模型与传统水文模型的应用效果,表明在特定情况下LSTM表现更佳。例如:Lees等[10]将LSTM同4个概念集总模型(TOPMODEL、ARNOVIC、PRMS、SACRAMENTO)进行比较,在英国流域的验证表明,LSTM在英格兰南部较干旱的流域表现更好。Kim等[11]比较了美国大陆4个流域的常用水文模型和机器学习模型,结果表明机器学习模型在高流量状态下精度较高,在径流模拟方面具有应用潜力。丁艺鼎等[12]将鲸鱼优化算法(WOA)与LSTM集成,构建WOA-LSTM模型,对横溪水库的模拟结果表明,较新安江模型,WOA-LSTM模型拥有更高的精度,预报结果更稳定。然而,上述研究均是对单个流域的预测居多,即仅利用特定流域的信息建模。
机器学习模型对水文资料数量有一定要求,因此短缺资料(乏资料)流域的机器学习建模是一个亟待解决的难题[13]。通过参数区域化[14]和迁移学习[15]的方法,将在源域训练的模型移用至目标域,实现知识的迁移使用,是目前应对上述问题的有效方法。Besaw等[16]将一个流域上训练的人工神经网络(ANN)移置到邻近流域进行应用,但精度并不理想。Kratzert等[17]基于LSTM进行降雨径流建模,并在美国17个水文响应单元上分别构建了区域化模型,展示了在区域尺度上训练的模型转移到单个流域应用的可能性。殷仕明等[18]在不同网络迁移策略和学习场景下,构建同流域/跨流域迁移模型,结果表明与不迁移网络相比,迁移后的网络更稳定且精度更高。上述这些研究的特点是构建的模型往往仅利用了区域内的降雨和流量信息,对影响洪水的地形地貌等信息利用不足。Ma等[19]做了进一步的研究:在考虑降雨径流信息的基础上,将流域地形地貌因子直接作为模型输入,在美国大陆上预先训练LSTM模型,并移用到其他大陆的流域中,实现了模型在较大空间范围的迁移学习。但该研究中,地形因子与预测量之间的关系完全依托于LSTM黑箱模型自行学习,就水文学的角度而言,在流域产汇流过程中,对流域内的任意两点,即使降雨相同但所处位置不同,其对流域出口断面洪水形成的影响也不同,如到出口断面的汇流路径越短、比降越大,该位置的降水对出口断面洪水过程的影响就越大,反之亦然。因此,在建立实际的区域化/迁移学习模型时,如何通过将水文气象及地形地貌等因子对水文过程影响的物理背景融入模型的构建中,以提升模型的物理可解释性和泛化能力,值得深入研究。
为此,本文提出一种新的LSTM区域化建模思路,即具有相似气候气象和水文条件的水文气候相似区为计算区域,在相似区内再按水文控制站划分子流域;采用泛归一化方法,将各子流域的降雨、流量、汇流路径长度及比降等要素分别进行归一化处理,以消除局地因素影响,构成计算区域建模的统一数据集;再基于此统一数据集,建立区域化LSTM洪水预报模型。本文以胶东半岛水文相似区为例,对提出的区域化LSTM模型进行应用,检验方法的有效性。
1 方法原理介绍
1.1 区域化LSTM洪水预报模型
LSTM是一种特定形式的循环神经网络模型(RNN),其在RNN模型的基础上通过增加门限(包括遗忘门、输入门、输出门)来控制信息的遗忘与更新。有效避免了训练过程中梯度爆炸与消失的问题,保证了长时记忆能力,更加适用于时间序列的处理[20-21]。LSTM等神经网络模型的本质是探究输入、输出因子之间的量化关系,因此需要较多数据用作模型率定。对于资料较缺乏的流域,一般难以直接建立LSTM模型进行洪水预报。本文以水文气候相似区为尺度建立区域化的LSTM模型,以解决资料较少流域的洪水预报问题。
对于同一水文气候相似区的各个流域,认为其产汇流规律较为一致或相似,因此可利用相似区内有资料流域的水文气象和地形地貌等数据,训练得到相似区的统一LSTM模型,以发挥诸多流域大数据的建模优势。对相似区内资料短缺的任一流域(预报断面),可将该流域资料与统一模型结合,从而解决因资料短缺带来的建模困难。
虽然水文气候相似区内的宏观水文、气候条件基本一致,但相似区内各流域的局地天气过程和下垫面条件往往仍有一定差异,所以各流域形成的暴雨洪水过程也并不相同。如图1所示,某一水文气候相似区内包含A~D等流域,其中A、C、D为嵌套流域,B为独立流域。显然,各流域面积、形状等各不相同,局地降雨过程也不尽相同,即使降雨过程一致,出口断面洪水过程也不会相同。所以在利用相似区内多流域资料进行区域化建模时,应先将相似区内各流域的要素进行归一化处理,以消除局地因素的影响并构建区域统一数据集,在此基础上建立区域化LSTM模型。

图1水文气候相似区示意
Fig.1Schematic of hydroclimatic similar zone
1.1.1 泛归一化处理方法
图2为水文气候相似区内任意一个流域的示意图,其中包含有多个子流域及对应的雨量站和水文站。显然,由于各子流域控制面积上的水文和下垫面要素不尽相同,使得各子流域水文站的流量对流域出口断面流量的贡献也不相同,不便于将各子流域的资料直接用于统一模型构建。因此,可先采用泛归一化方法,消除局地因素影响,构建该流域的建模统一数据集。具体过程如下:

图2流域示意
Fig.2Schematic of a basin
(1) 雨量归一化处理
选用最大最小归一化方式进行流域面平均雨量归一化处理,计算公式为:
(1)
式中,P*为任一子流域归一化后的面平均雨量指标,P为子流域由观测值计算的面平均雨量,Pmin为整个流域的最小面雨量,Pmax为整个流域的最大面雨量。
(2)流量归一化处理
流量归一化处理包括两个步骤:先引入流量模数以消除各子流域面积大小对流量的影响,其值代表了单位面积的产流情况,以反映本流域下断面特征对流量的影响;再对各水文站控制面积的流量模数在整个流域尺度上进行泛归一化处理,即用该子流域到出口断面的汇流路径长度和比降与流量模数组合,以反映上游子流域(水文站)流量对下游流量的汇流影响。以图2中水文站a处流量的归一化处理为例,过程如下:
① 子流域水文站流量模数计算:
(2)
式中,Ma为水文站a的流量模数,Qa为水文站a的实测流量,Aa为水文站a的控制面积。
② 子流域水文站流量模数归一化:
(3)
式中,M*a为水文站a的归一化后流量模数指标;Mmin为整个流域的流量模数最小值;Mmax为整个流域的流量模数最大值;Ma同上。
③ 子流域水文站至出口断面汇流路径长度归一化处理
各子流域水文站到流域出口断面的汇流路径越长,相同情况下其对流域出口断面流量的影响就越小,反之亦然。本文通过将各子流域水文站到流域出口断面的汇流路径长度同流域最大汇流路径长度相比的方式构建汇流路径长度归一化指标。计算公式为:
(4)
式中,αa为水文站a的汇流路径长度归一化指标;La为水文站a到流域出口断面的汇流路径长度;L为流域最长汇流路径长度。
④ 子流域水文站至出口断面比降归一化处理
各子流域水文站到流域出口断面的比降越大,洪水的汇流时间越短,洪水衰减(坦化)越小,相同条件下对流域出口断面流量的影响越大,反之亦然。本文通过将水文站到流域出口断面比降同流域最大比降相比的方式构建比降归一化指标。计算公式为:
(5)
式中,βa为水文站a的比降归一化指标;Ia为水文站a到流域出口断面的比降;I为流域最大比降。
⑤ 归一化地形地貌-流量因子
为简化模型构建,可以进一步将M*a、αa、βa三个要素进行综合。显然, M*a与αa呈反比关系,与βa呈正比关系,所以将三者合成形成新的地形地貌-流量因子指标(记为xq):
(6)
式中,xq为地形地貌-流量因子指标;M*a、αa、βa定义同前。
需要说明的是,对嵌套流域(如图1中的A流域)最下游出口断面水文站的流量数据,或只有出口断面一个水文站的独立流域(如图1中的B流域),则只进行流量的模数计算及模数数值归一化(步骤①②),不再做其他处理。
1.1.2 统一数据集构建
通过上述的归一化处理,得到水文气候相似区内各水文站的雨量及地形地貌-流量合成因子的归一化数据(P*,xq),由于消除了各流域局地因素影响,所以可将各流域的归一化数据合并,构成区域建模的统一数据集。
综上,通过泛归一化处理,构建了水文气候相似区内水文气象和主要地形地貌要素的归一化数据,并通过将流量因子与汇流路径长度和比降因子综合,最终得到相似区的统一建模数据集;为方便后文描述,记为(xp,xq),分别代表雨量因子指标和地形地貌-流量因子指标两类数据。
1.1.3 模型训练及应用
本文采用不同预见期构建不同预报模型的方式进行区域LSTM建模。设当前时刻为t,预见期的总长度为s,对未来任一时刻t+c(1≤c≤s)的流量预报,以t及之前jΔt的逐时段流量数据、t及之前kΔt的逐时段雨量数据以及预见期内逐时段雨量数据为输入,以t+c时刻流域控制断面处的流量作为目标输出,构建区域化LSTM模型(记为LSTM-c)。
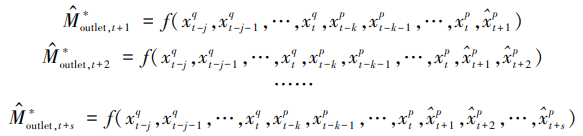
(7)
式中,为t+c时刻流域控制断面处的归一化后流量,其中1≤c≤s;为t-r时刻的地形地貌-流量输入因子,其中0≤r≤j;xpt-y为t-y时刻的雨量输入因子,其中0≤y≤k;为t+z时刻的雨量输入因子,其中1≤z≤s。
需要说明的是,在利用统一数据集训练LSTM-c模型时,t~t+c时间段内的雨量输入因子(xp)以实测数据代入,但在采用模型进行实时洪水预报时,需要采用预见期内的预报雨量作为输入。另外,由于模型的输出为归一化后的流量数据,因此需要再将其进行反归一化处理,最终得到流域出口断面的预报流量。
1.2 评价指标
选取洪量平均绝对百分比误差(mean absolute percentage error of flood volume,VMAPE)、洪峰平均绝对百分比误差(mean absolute percentage error of flood peak,QMAPE)、峰现时间绝对误差(error of peak time,EPT)以及纳什效率系数(Nash-Sutcliffe efficiency coefficient,NSE)作为模型整体精度评价指标。具体计算公式如下:
(8)
(9)
(10)
(11)
式中,n为总洪水场次数;Vobs为实测洪量;Vsim为模拟洪量;Qm,obs为实测洪峰流量;Qm,sim为模拟洪峰流量;tm,obs为实测洪峰出现时间;tm,sim为模拟洪峰出现时间;N为资料序列长度;Qobs(t)为t时刻的实测流量;Qsim(t)为t时刻的模拟流量;为平均实测流量。
2 研究区概况及数据
2.1 研究区概况
本文选取胶东半岛水文气候相似区进行应用研究。胶东半岛地跨青岛、烟台、威海三市,地处中国华北平原东北部沿海地区。胶东半岛属暖温带湿润季风气候,多年平均降水量为650~850 mm,且年内分配不均,汛期降水量占全年的60%以上。胶东半岛水系发源于中部山地,南北分流,独流入海。河川径流洪枯悬殊,汛期径流量占全年径流量的70%~80%[22]。研究区内的测站分布情况如图3所示。
2.2 研究数据
区域化模型的构建需要综合考虑水文因素以及流域特征因素。考虑到资料的可获得性以及预报模型在实际应用中的可操作性,本文选取研究区10个流域的数据(图3)。水文数据包括降雨及流量数据,时间范围为2010—2021年,来自雨量站、水文站实测。以上所有数据均经过次洪挑选、数据清洗、格式转换,并处理成逐小时时间序列。流域特征数据包括控制面积、汇流路径长度以及比降,均利用数字高程模型[23](SRTM 90 m DEM)提取获得。此外,本文通过滑动窗口选样[24]的方式,利用现有场次洪水资料组建样本。研究区内各流域的基本信息如表1所示。其中,洪水场次个数为该流域内所搜集到的场次洪水的数量;洪水样本数量为对每一场洪水通过滑动窗口选样方式,构造出用于LSTM建模的样本(雨量因子指标xp和地形地貌-流量因子指标xq组成的样本)的总数。
表1流域基本信息
Tab.1 Basic information of the basins


图3胶东半岛水系、站网分布
Fig.3Schematic of river, station work in Jiaodong Peninsula
3 结果分析
区域化模型的构建主要是为了解决因部分流域资料缺乏,难以支撑数据驱动类模型构建或模型精度不高等问题。为此,本文设计了两种区域化模型来验证在不同实用场景下的适用性:①区域化模型Ⅰ:扣除目标流域数据,仅选用相似区内其他流域数据参与区域化建模,并将目标流域数据用作模型验证,其目的是为了测试区域化模型在没有参与建模的流域的泛化能力;②区域化模型Ⅱ:目标流域的部分资料与相似区内其他流域数据共同参与区域化建模,并根据目标流域预留的部分数据作模型验证,以检验目标流域少量数据加入对区域化模型精度的影响。此外,在目标流域上建立仅采用本流域数据训练的模型(即单流域模型)作为基准模型,以对比分析区域化模型的优势。在本文所选定的胶东半岛研究区中,各流域的洪水场次个数并不多,均属于乏资料流域,所以选取数据条件相对较好的团旺、臧格庄两个流域作为目标流域进行实证分析,模型精度统计结果见表2。
由表2可知,区域化模型Ⅰ在各预见期中的VMAPE、QMAPE与EPT值分别低于6.1%、14.3%与7.0 h,NSE值高于0.79,4项指标值均在合理范围内,表明区域化模型具有较强的泛化能力,可以应用于相似区内未参与建模流域的洪水预报。区域化模型Ⅱ在各预见期中的VMAPE、QMAPE、EPT以及NSE值分别介于1.0%~5.8%、1.6%~14.1%、1.0~6.7 h以及0.82~0.99区间内,总体表现略优于区域化模型Ⅰ。说明在建立区域化模型Ⅱ时引入目标流域数据,因融入了目标流域暴雨洪水的信息,可进一步提升其预报精度。样本数量增加也可能是导致精度提升的因素之一,但实际作业预报中,对基于机器学习的大数据建模问题,资料条件一般都不够充分,所以需要共同使用本流域的有限资料以及区域数据信息。单流域模型在预见期较短时也展现出较高的预报精度,但整体上低于区域化模型,特别是随着预见期的增长,预报精度下降较快。如当预见期为6 h时,团旺、臧格庄的单流域模型的QMAPE值分别为21.9%和29.9%,超出20%,未能满足《水文情报预报规范》(GB/T22482—2008)所规定的合格标准;且团旺的单流域模型EPT为11.0 h,显著高于同一时段内两个区域化模型的相应EPT值。显然,由于目标流域场次洪水个数较少,仅以目标流域的数据训练模型,未必能学习到输入输出要素之间的内在关系,导致模型精度及鲁棒性不高。
表2区域化模型和单流域模型的验证精度
Tab.2 Accuracy of regional models and single-basin models in validation period

本文以团旺流域20170804和臧格庄流域20130726两场洪水过程为例,绘制3个模型不同预见期下的验证结果对比图(分别见图4、图5)。两种区域化模型对洪峰和洪量均给出了较满意的预报结果,与实际洪水过程基本相符,均优于单流域模型结果(区域化模型Ⅱ整体更优);特别是,单流域模型对洪峰流量往往出现低估情况(图4、图5)。分析原因是单流域模型的建模资料匮乏,因而模型难以充分学习到输入输出因子之间的复杂相关关系,导致模型的稳定性不足。从地理位置上看,团旺和臧格庄流域相距较远(分别位于胶东半岛的中南部和东北部地区),但统一的区域化模型在两个流域均取得较好效果,这在一定程度上表明区域化模型对相似区内的各流域均具有较强的泛化能力与鲁棒性。

图4团旺流域20170804号洪水实测流量过程与预测流量过程对比
Fig.4Comparison of measured and predicted discharge process of flood 20170804 in Tuanwang Basin

图5臧格庄流域20130726号洪水实测流量过程与预测流量过程对比
Fig.5Comparison of measured and predicted discharge processes of flood 20130726 in Zanggezhuang Basin
4 结论与展望
本文建立了一种基于泛归一化处理方法的区域化LSTM洪水预报模型,并以胶东半岛作为研究区域进行示例研究,主要结论如下:
1)通过泛归一化处理方法构建区域化洪水预报模型,消除局地因素的影响,处理后水文气候相似区内各流域数据的集合可共同用于构建区域化模型,实现了相似区内任一流域的洪水预报,为乏资料地区的洪水预报提供一种有效途径。
2)在胶东半岛的应用示例表明,对乏资料流域的洪水预报,根据水文气候相似区内多流域资料构建的区域化模型,其精度整体优于仅由单流域资料率定的模型,且在区域化模型构建过程中,融入目标流域的少量数据,可以使预报精度得到进一步提升。
3)本文构建的区域化模型考虑了流量、前期雨量以及控制面积、汇流路径、比降等因素,这些因素未必能反映洪水过程的全部信息,未来在区域洪水影响因素选取及综合等方面值得进一步探讨。另外,由于本次参与区域化建模的流域数相对较少且各流域资料情况也较为匮乏,所以本文未能深入探讨流域个数及样本数量对模型性能的影响问题,未来可以对这些问题进行深入探讨。
